I have recently been working on a little project that had a very simple purpose: Put in a map around 200 markers about where to find dog waste bags disposals in a town. This might have little intersection with biodiversity, but I think some of the ideas might be useful for other people.
The idea was to create a simple map/widget that could be managed by a non technical person and did not require setting up databases and hosting services. The kind of project you want to set up and forget more or less about it.
Well, the simplest thing to manage the location of the disposal is something like and spreadsheet and the internet version for that is
Google Spreadsheets. I started thinking on using the
Spreadsheet mapper, but it has far too much options, and we did not really need to share a KML file. So I thought creating something simpler. Just my required columns on the document and connect from
Google Maps for Flash. So we wo
uld be able to just distribute the Flash SWF file and it will take
care of connecting to Google Spreasheets, download the data and display it on the map.
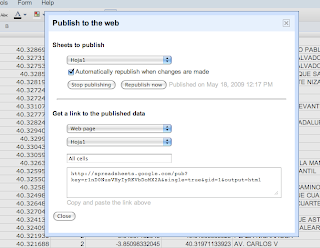
Sounds very easy no? Just publish the spreadsheet, setting automatically republish on changes, select the CSV format, and you get a perfect API to your data.
Look at ours for example.
Then on the Flex app is as simple as parsing a CSV and dynamically create the needed markers.
The only problem is... Google does not like crossdomain.xml f
Therefore we were gonna have to create a proxy server to bypass the
security restrictions, but we really did not like the idea of havi
ng to set up one just for this small thing and maintaining it.
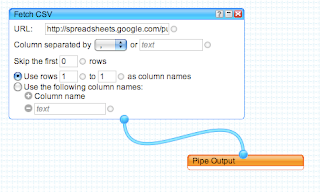
So I decided to take a look at
Yahoo Pipes to
bypass the crossdomain issue. You just need to create a simple Pipe that consumes the CSV from spreadhseets and output it as JSON. Yahoo pipes has an open crossdomain file, so no problems.
Here is my pipe for example. Very simple and effective.
The project had to deal also with transforming UTMs into Latitude/Longitudes and some other issues, but I think this overview is enough. The source code is so simple that I dont think its needs more explanations.
We would like to start using the Google Data API much more in the future, specially the shiny new
Google Maps Data API, but I think this makes for a very simple solutions for lot of small projects like this one.
And finally, Google, please start setting up crossdomain files on your APIs, or at least, explain us why you dont do so... the actual situation is very frustrating.